
不算什么深入的研究,主要是了解下JPPF中类的加载和隔离机制。
JPPF中类的加载采用的是分布式类加载技术。这样既可在Node节点运行在node上并不存在的类。也就是类可以仅在用户的Client端存在。
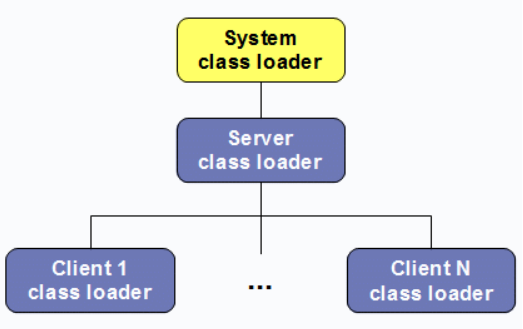
如图,JPPF的class loader大致分三层。
System class loader是由JVM控制的加载器,用于启动node节点。在大多数JVM中是,该loader是java.net.URLClassloader的实例。Server class loader是类AbstractJPPFClassloader的实现,提供了远程访问server端classpath中的类和其他资源的功能。该loader在node连接到server端的时候创建,断开连接的时候销毁。其父loader为System class loader。Client class loader也是AbstractJPPFClassloader类的实现,提供了远程访问一个或多个客户端上的类和资源的功能。该loader在客户端提交任务的时候创建。一个node可能会持有很多client class loader。JPPF的node节点仅持有一个与Server的连接,该连接被所有的loader共享,这样可以避免并发时潜在的的一致性,同步和冲突等问题。
Java的classloader是先从parent loader开始加载的饿,下图展示了node节点加载类的过程
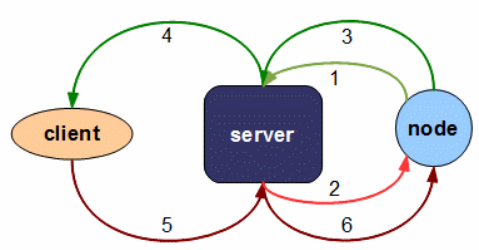
node节点先从server节点请求class。如果server节点存在class,则直接加载返回。
如果class仅在client端存在,则会先访问server,server无,再通过server定位client,访问client端的class。在JPPF框架里,每个client都有一个唯一的UUID,用于唯一标识该client。Node节点便可根据此UUID识别出当前classloader读取的是哪个client的class
每个Server也有唯一的UUID标识,这样就可以实现链式类加载:
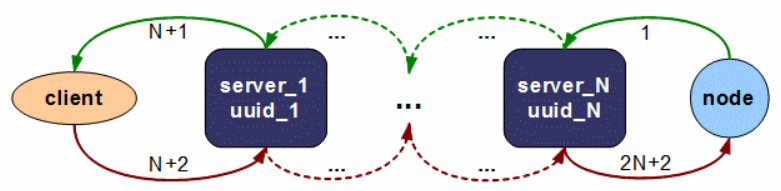
需要注意的是,在这种情况下,node节点仍然只持有一个server classloader,仅连接跟它直接关联的server。
UUID与classloader
使用client端UUID,即可实现不同的client端在执行同一个任务的时候的classloader隔离,因为uuid不同,会使用不同的classloader加载类。不过,如果同一个UUID提交了两个不同版本的任务class,则有可能出现冲突和错误。 你也可以手动指定client端的UUID,这样classloader即可重用。哪怕你重连client也可以重用同一个classloader。不过,此时随之而来的问题就是在客户端修改的版本可能不会在node端自动生效,不同的版本还可能造成冲突。这时,你可以重启node或者更换UUID使node重新加载class。任务预部署
对于大任务,如果担心每次走网络效率低,根据上面介绍的classloader机制,自然想到可以预先将任务文件部署到server或者node节点。不过此时需要自己管理好部署的版本,所谓各有利弊。不过,如果任务版本稳定的话,建议采用此种方式。classloader缓存池
为了避免加载过多的类造成内存溢出,JPPF在node端增加了classloader缓存池大小的设置,如果超过上限,则会销毁最老的classloader。jppf.classloader.cache.size = n
本地缓存资源文件
当调用getResourceAsStream(), getResource(),getResources() or getMultipleResources()方法的时候,class loader会缓存非类定义的文件至内存或者本地文件系统中。这样会避免再次请求该文件时候的网络访问,提高效率。你可以指定缓存在内存中还是文件系统中:# either “file” (the default) or “memory“
jppf.resource.cache.storage = file
文件的保存路径当然也是可以配置的,默认是系统临时文件夹System.getProperty("java.io.tmpdir").:
jppf.resource.cache.dir = some_directory
JPPF server中的类缓存
JPPF的服务端会在内存中缓存被classloader加载进来的类和其他资。这样就可以避免与客户端的频繁的网络访问,从而提高执行速度。你也无需担心内存溢出的问题,因为这种缓存采用的是软引用,这样缓存的类就可以在必要的时候被JVM的垃圾回收机制回收。在一般情况,该缓存还是可以显著的提升效率的。
Class loader代理模型
JPPF默认采用的是”父优先“的类加载模型,也就是上面我们介绍的模型。上述模型虽然好用,但是类的加载顺序就相对固定,也就不能最大化的优化加载效率。因此,JPPF通过继承URLClassLoader,复写并开放addURL接口(jdk里是protected,JPPF为public),使得用户的自己开发任务可以直接调用该方法,形成对classloader的一种扩展。用户可调用addURL方法,指定自己想要加载类的地址。此时JPPF classloader的加载顺序会出现变化,从大的步骤看,会先查找指定的URL classpath:* 从clientclassloader入手:代理到server的classloader
* server的classloader: 先仅查找用户指定的URL classpath * 如果找到类,则结束查找* 否则,回到client的classloader,也仅查找URL的classpath * 如果找到,结束查找。
此书,如果仍未找到,则回到前面介绍的通过网络的查找顺序。
概括来说,就是如果URL优先的代理模型激活,则node会先从本地层级中查找URL指定的classpath,然后在网络上通过server查找。有三种指定代理模型的方式,最简单的就是直接配置在node节点的配置文件中:# possible values: parent | url, defaults to parent
jppf.classloader.delegation = parent
下载文件
如我们之前的介绍的,我们可以通过addURL(URL)方法,动态指定加载类的URL地址,那么自然想到,我们可以通过先将文件下载到本地,然后指定URL地址,从而进行本地加载,以提到效率。在AbstractJPPFClassLoader类中,有方法:
public URL[] getMultipleResources(final String…names)可以帮你同时下载多个文件到本地。以上只是我了解到的JPPF中关于类加载部分的设计和实现。从已有掌握来看,JPPF考虑的还是非常全面周到的,隔离、效率、一致性都有考虑,应该说对并行计算来说,很有保障。
转载至:http://www.coderli.com/jppf-classloader